Web Application Analysis
by
ted
Abstract
The goal of this project is to use machine learning to classify web applications based on technologies and frameworks such as WordPress or Django. Each different technology and framework comes with its own vulnerabilities, so with the purpose of bug bounty hunting identifying what gears are turning behind a website will help immensely in the reconnaissance phase.
The code without annotations can be found here.
Step 1 (data collection)
For this step we will need to make a web scraper to collect the data we need. The information we will be looking for is HTTP headers, meta tags, linked js and CSS files.
import pandas as pd
import requests
from bs4 import BeautifulSoup
# Read websites from CSV file
def read_from_csv(filename):
try:
df = pd.read_csv(filename)
return df["URL"].tolist()
except Exception as e:
print(f"Error reading file: {e}")
return []
# Add 'https://' to the URL if it's missing
def add_https_prefix(url):
if not url.startswith(('http://', 'https://')):
url = 'https://' + url
return url
# Analyze a single website
def analyze_website(url):
try:
# Ensure URL has https:// prefix
url = add_https_prefix(url)
# Send HTTP GET request
response = requests.get(url, timeout=20)
soup = BeautifulSoup(response.text, "html.parser")
# Extract HTTP headers
headers = response.headers
# Extract meta tags
meta_tags = {meta.get("name", "").lower(): meta.get("content", "") for meta in soup.find_all("meta")}
# Extract linked JavaScript files
scripts = [script.get("src") for script in soup.find_all("script") if script.get("src")]
# Extract linked CSS files
stylesheets = [link.get("href") for link in soup.find_all("link", rel="stylesheet")]
# Extract HTTP server header (if present)
server = headers.get("Server", "Unknown")
return {
"URL": url,
"Server": server,
"Meta Tags": meta_tags,
"Scripts": scripts,
"Stylesheets": stylesheets,
}
except Exception as e:
print(f"Error scraping {url}: {e}")
return {
"URL": url,
"Server": "Error",
"Meta Tags": {},
"Scripts": [],
"Stylesheets": [],
}
# Main logic
csv_file = "C:\\Users\\ibrah\\Downloads\\ba8d8eed85b0c289a05c750b3d825f61-6827168570520ded27c102730e442f35fb4b6a6d\\ba8d8eed85b0c289a05c750b3d825f61-6827168570520ded27c102730e442f35fb4b6a6d\\websites1.csv"
websites = read_from_csv(csv_file)
if not websites:
print("No websites found in the CSV file.")
else:
# Scrape all websites
results = [analyze_website(url) for url in websites]
# Save results to CSV
output_file = "web_analysis.csv"
df = pd.DataFrame(results)
df.to_csv(output_file, index=False)
print(f"Results saved to {output_file}")
- the script for extracting the data we need
The CSV file of websites we are using can be found here.
But why are we gathering this specific data? Let’s look at each piece of information we are collecting and understand why we are collecting it.
Why HTTP Headers?
HTTP headers give us information about the server, different content types and security configurations. For example headers like SERVER or x.com-powered-by can tell us what server (Apache, Nginx, etc) and what frameworks (Django, Express, etc) are in use.
Why Meta tags?
Meta tags give us information about the purpose, author and SEO (Search Engine Optimization) details of a website. For example the viewport tag which allows control of the user’s visible area of a webpage can tell us if the website is intended for mobile use.
Why JavaScript files?
JavaScript files determine the dynamic behavior and functionality of a website. For example URLS and naming patterns of JS files can show us third party services like Google Analytics or libraries such as React and Angular.
Linked CSS Files
CSS files are used to define the website’s styling and layout whose structure and content can be used to find frameworks or design systems like Bootstrap or Tailwind.
But why?
In the machine learning sense we want our model to detect the frameworks and technologies based on the information we are collecting and in the bug bounty sense we want to identify frameworks and technologies to make reconnaissance easier. CVE-2024-45231 which allows malicious persons to find the email of a user based on response status of a password reset affects specific Django versions but not other frameworks like Flask or Laravel.
Step 2 (Data cleaning)
Now that we have our CSV file of data we need to format it into a pandas data frame so we can understand it better.
import pandas as pd
import ast
# Load csv file
df = pd.read_csv("web_analysis.csv")
# Extracting relevant columns
df_cleaned = pd.DataFrame({
"URL": df["URL"],
"Server": df["Server"],
"Title": df["Meta Tags"].apply(lambda x: ast.literal_eval(x).get('og:title', 'N/A') if pd.notna(x) else 'N/A'),
"Description": df["Meta Tags"].apply(lambda x: ast.literal_eval(x).get('description', 'N/A') if pd.notna(x) else 'N/A'),
"Number of Scripts": df["Scripts"].apply(lambda x: len(ast.literal_eval(x)) if pd.notna(x) else 0),
"Number of Stylesheets": df["Stylesheets"].apply(lambda x: len(ast.literal_eval(x)) if pd.notna(x) else 0),
})
- we keep the server and URL info as is
- we parse the meta tags to be stored as strings in our csv file
- we count the scripts and stylesheets and store them as lists in the csv file
- we use
ast.literal_evalto convert between data types
# Save the cleaned DataFrame to a new CSV file (just in case)
df_cleaned.to_csv("web_analysis_cleaned.csv", index=False)
df_cleaned.head()

- nice
Extracting JS and CSS file info
Now to add info from the JS and CSS filenames to our data frame. We will need the regex library to identify the common framework names from the filenames in our csv file.
import re
# Load the dataset from CSV
file_path = "C:\\Users\\ibrah\\Downloads\\ba8d8eed85b0c289a05c750b3d825f61-6827168570520ded27c102730e442f35fb4b6a6d\\ba8d8eed85b0c289a05c750b3d825f61-6827168570520ded27c102730e442f35fb4b6a6d\\web_analysis_with_frameworks.csv"
df = pd.read_csv(file_path)
# Patterns for detecting common frameworks/libraries
framework_patterns = {
"jQuery": r"jquery",
"Bootstrap": r"bootstrap",
"React": r"react",
"Vue.js": r"vue",
"Angular": r"angular",
"Tailwind": r"tailwind",
"Foundation": r"foundation",
"Materialize": r"materialize",
"D3.js": r"d3",
"Moment.js": r"moment",
"Three.js": r"three",
}
- here we are telling regex what words we are looking for and what library or framework they correspond to
# Preprocessing columns to handle NaN, None, or invalid data
def preprocess_file_list(file_list):
if pd.isna(file_list) or not isinstance(file_list, str): # Handle NaN or None
return "[]"
try:
if isinstance(eval(file_list), list): # Ensuring valid list
return file_list
except:
pass
return "[]" # Defaulting to empty list if parsing fails
df["Scripts"] = df["Scripts"].apply(preprocess_file_list)
df["Stylesheets"] = df["Stylesheets"].apply(preprocess_file_list)
- we are cleaning and preprocessing the
ScriptsandStylesheetscolumns in our data frame by formatting into a python list - for rows with no files or no words from our
framework_patternswe want a default[]to signify an empty list
# Function to extract frameworks/libraries from file names
def extract_frameworks(file_list, patterns):
extracted_frameworks = set()
try:
file_list = eval(file_list) # Convert string representation of list to Python list
for file in file_list:
for framework, pattern in patterns.items():
if re.search(pattern, file, re.IGNORECASE):
extracted_frameworks.add(framework)
except Exception as e:
print(f"Error processing row: {file_list}, Error: {e}") # Debugging statement
return ",".join(extracted_frameworks)
- we attempt to analyze
file_listwhich holds the JS and CSS file names - doing this by matching patterns specified by
regexin each file name to the popular frameworks/libraries we specified - we compile our results into a string
# Extracting Scripts and Stylesheets columns
df["Frameworks_JS"] = df["Scripts"].apply(lambda x: extract_frameworks(x, framework_patterns))
df["Frameworks_CSS"] = df["Stylesheets"].apply(lambda x: extract_frameworks(x, framework_patterns))
- we are creating two new columns that have just the names of the JS and CSS frameworks/libraries
Now let us look at the two data frames we have created,
df[["Scripts", "Frameworks_JS"]]

df[["Scripts", "Frameworks_CSS"]]

Both data frames seem to be formatted as intended. We have the [] to indicated an empty list and other wise we have our list of JSS and CS frameworks/libraries.
Merging data frames
We can merge the two data frames we created with the main data frame that holds the URL, Server, etc. info.
# Merging data frames
df_merged = pd.merge(df,df_cleaned)
df_merged.head()
- we seem to have some conflicting information
The problem we face is that we do have JS and CSS files however the frameworks are not showing up in the respective columns. This is most likely because we only provided 11 total frameworks for regex to match, so the filenames have frameworks that we have not specified.
Well let’s add to our list of frameworks then,
# Patterns for detecting common frameworks/libraries
framework_patterns = {
"jQuery": r"jquery",
"Bootstrap": r"bootstrap",
"React": r"react",
"Vue.js": r"vue",
"Angular": r"angular",
"Tailwind": r"tailwind",
"Foundation": r"foundation",
"Materialize": r"materialize",
"D3.js": r"d3",
"Moment.js": r"moment",
"Three.js": r"three",
"Express": r"express",
"Next.js": r"next",
"Node.js": r"node",
"Svelte": r"svelte",
"NestJS": r"nest",
"NuxtJS": r"nuxt",
"Gatsby": r"gatsby",
"Bulma": r"bulma",
"Blaze UI": r"blaze",
"Tachyons": r"tachyons",
"Fomantic UI": r"fomantic",
"Spectre": r"spectre"
}
- We’ve added a few more popular frameworks
- ouch looks like we only matched Next.js from our list
Let’s cleanup and see how many missing rows we actually have. First we really do not need the Scripts and Stylesheets column anymore so let’s remove those.
# Dropping the Scripts and Stylesheets columns
df_merged_dropped = df_merged.drop(columns = ["Scripts", "Stylesheets"])
df_merged_dropped.head()

- perfect
# Counting how many times each value occurs
print(df_merged_dropped["Frameworks_JS"].value_counts())

# Counting how many times each value occurs
print(df_merged_dropped["Frameworks_CSS"].value_counts())

We have a very large portion of no values for the JS and CSS frameworks. This is likely due to the amateurity of our web scraper which wasn’t able to collect scripts from a lot of the websites.
However when printing the value counts for the Scripts and Stylesheets columns we note that the empty values are 333 and 363 respectively. This means we have 308 unknown JS and 459 unknown CSS framework entries in their respective columns.
Let’s try adding some more frameworks to our regex list then,
"Safe,js": r"safe",
"Vanilla Framework": r"vanilla"
- adding these frameworks only decreases the empty JS count by 2 and the empty CSS count by 1
Step ?? (redefining the problem)
Ok this is proving to be very complex, in addition to our empty framework entries I also noticed,
- in the CSS column we have JS frameworks and vice versa
We need to redefine what we are trying to do, originally our goal was to identify the frameworks and technologies in use from the information we collected but the information we collected already identified those technologies.
Let me suggest an idea, for each framework or technology we can find the amount of CVEs it has via a database such as cve.mitre.org, using this information we can assign each URL a vulnerability score depending on the amount of CVEs it has.
Step 3 (continuing data manipulation)
# Combine the Frameworks_CSS and Frameworks_JS columns into a single column
df["Frameworks_Combined"] = df["Frameworks_JS"].fillna('') + df["Frameworks_CSS"].fillna('')
- combines the two columns
# Merging the columns we want
df2 = pd.merge(df,df_merged_dropped)
# Dropping the unwanted columns
df3 = df2.drop(columns = ["Scripts", "Stylesheets", "Frameworks_JS", "Frameworks_CSS"])

Our df3 looks proper.
Meta Tags
So far we’ve mainly focused on the scripts and style sheets. Let’s try to extract data from the Meta Tags column.
meta_technologies = {
"WordPress": r"WordPress",
"Joomla": r"Joomla",
"Drupal": r"Drupal",
"Shopify": r"Shopify",
"Magento": r"Magento",
"WooCommerce": r"WooCommerce",
"Angular": r"ng-app",
"React": r"React",
"Vue.js": r"vue-meta",
"Google Analytics": r"google-site-verification",
"Matomo": r"Matomo|Piwik",
}
- wordlist of common technologies
# Function to extract technologies from the meta tags
def extract_technologies_from_meta(meta_tags, patterns):
detected_technologies = set()
for tech, pattern in patterns.items():
if re.search(pattern, meta_tags, re.IGNORECASE):
detected_technologies.add(tech)
return list(detected_technologies)
# Creating data frame with the technologies column
df_tech = pd.DataFrame({"URL": df["URL"], "Technologies": df["Technologies"]})
- extracting words from the meta tags
Final data frame?
Nothing in the Title or Description has anything of use to us so we can remove those as well.
- nothing that will help us here
- or here
CVE Search
What is a CVE? A CVE (Common Vulnerabilities and Exposures) is a list of publicly disclosed computer security flaws. A public security flaw gets slapped with an ID and becomes a CVE.
For our CVE score we have 2 dimensions to look at, the amount of CVEs and the actual CVE rating. CVE ratings range from 0-10 with higher number meaning greater security impact.
If we search for a framework such as node.js,

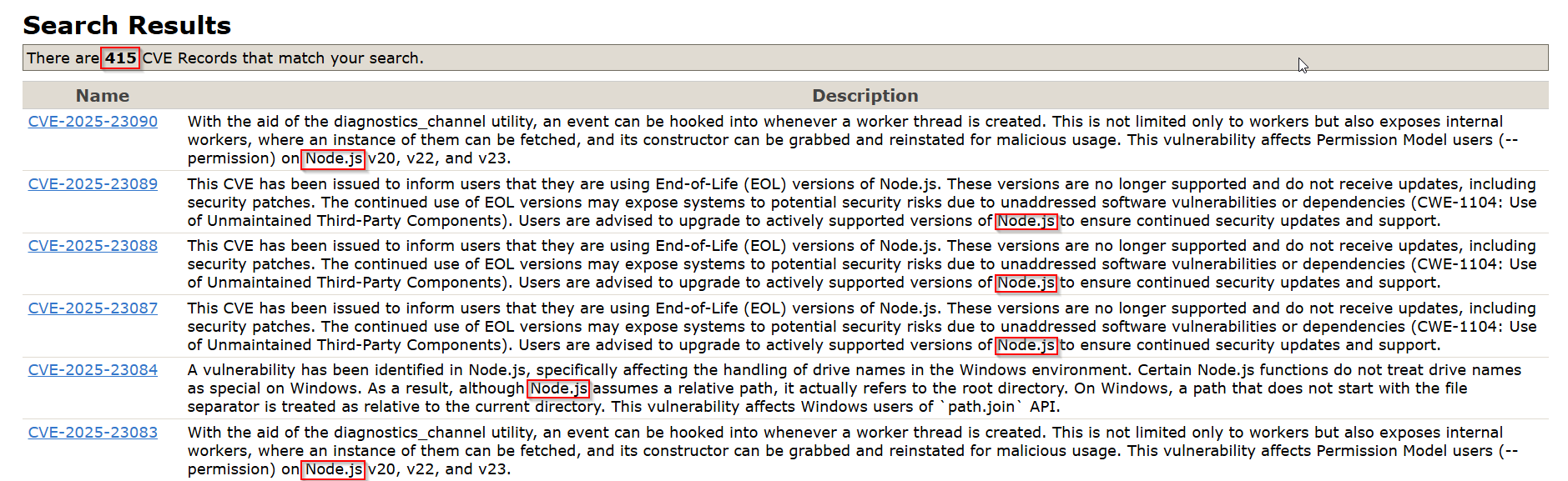
- there are 415 results for CVE’s related to node.js
Dead end?
They way we have defined our problem we are taking CVE scores for each technology and then adding a final score column which adds up the scores for each URL. This means there is a direct linear relation where $technology1 + technology2 + … = finalscore$. As a consequence there is no need for machine learning since we already have the relation between the inputs and the output. Even if we come up with a more complex relation between the CVE scores for technologies and the final score, there will still be a relation. Therefore we will always have an equation linking the inputs and outputs nulling any reason for using machine learning.
At least we have learned that we cannot force machine learning on any problem regarding data.
Stay tuned for more data science perhaps next time we can create a data set that will be more kind to us :3
tags: